Allotaxonometry and rank-turbulence divergence: a universal instrument for comparing complex systems
Abstract
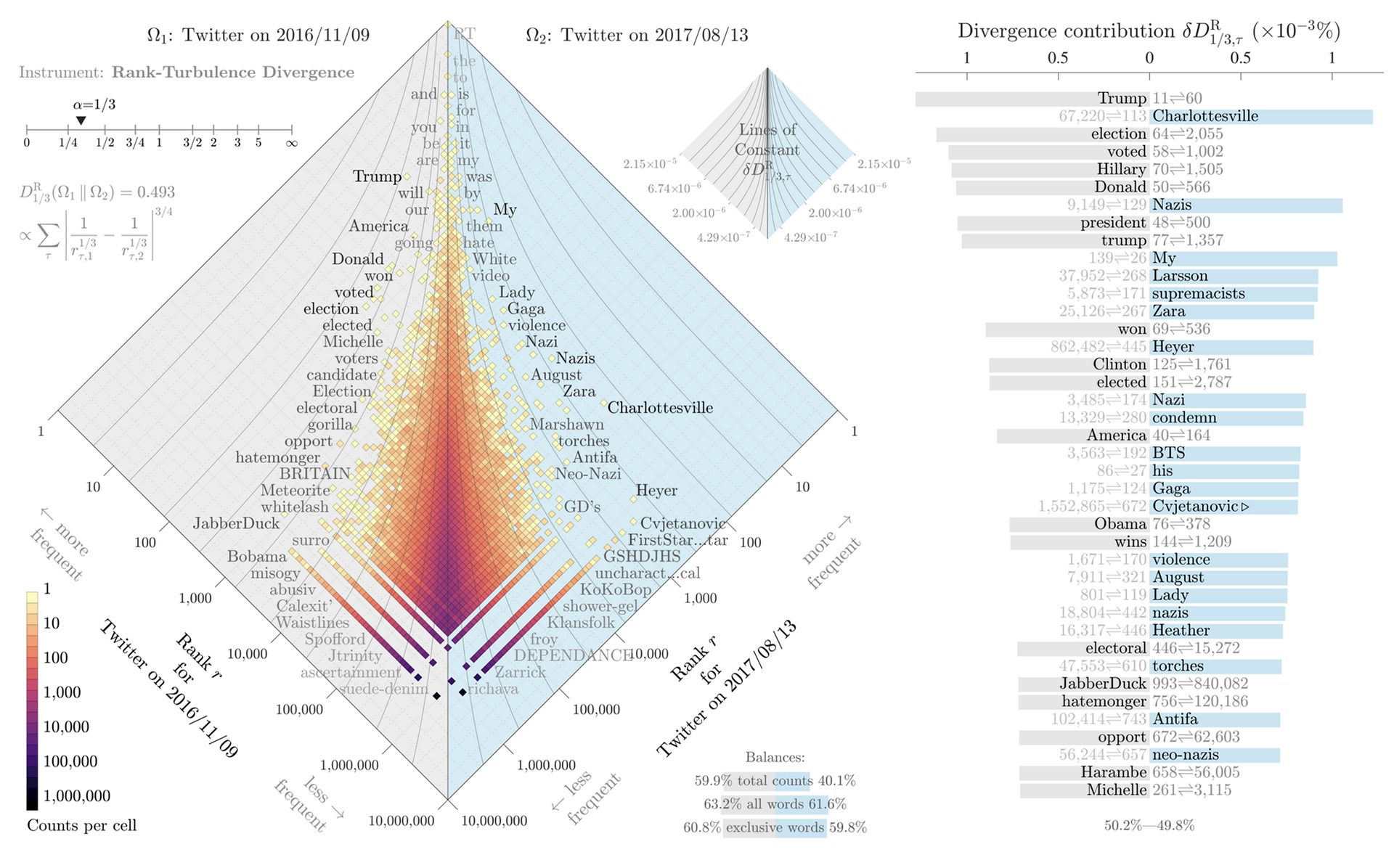
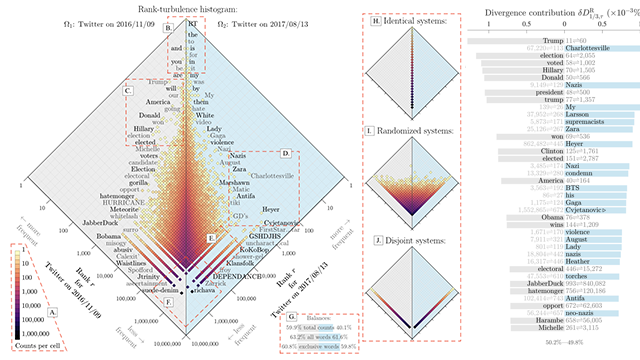
Complex systems often comprise many kinds of components which vary over many orders of magnitude in size: Populations of cities in countries, individual and corporate wealth in economies, species abundance in ecologies, word frequency in natural language, and node degree in complex networks. Here, we introduce ‘allotaxonometry’ along with ‘rank-turbulence divergence’ (RTD), a tunable instrument for comparing any two ranked lists of components. We analytically develop our rank-based divergence in a series of steps, and then establish a rank-based allotaxonograph which pairs a map-like histogram for rank-rank pairs with an ordered list of components according to divergence contribution. We explore the performance of rank-turbulence divergence, which we view as an instrument of ‘type calculus’, for a series of distinct settings including: Language use on Twitter and in books, species abundance, baby name popularity, market capitalization, performance in sports, mortality causes, and job titles. We provide a series of supplementary flipbooks which demonstrate the tunability and storytelling power of rank-based allotaxonometry.
Authors
Peter Sheridan Dodds
Joshua R Minot
Michael V Arnold
Thayer Alshaabi

David Rushing Dewhurst
Tyler J Gray
Morgan R Frank
Andrew J Reagan
Christopher M Danforth
Citation
Allotaxonometry and rank-turbulence divergence: a universal instrument for comparing complex systems
Peter Sheridan Dodds, Joshua R Minot, Michael V Arnold, Thayer Alshaabi, Jane Adams, David Rushing Dewhurst, Tyler J Gray, Morgan R Frank, Andrew J Reagan, and Christopher M Danforth. EPJ Data Science. 2023. DOI: 10.1140/epjds/s13688-023-00400-x
PDF | Preprint | DOI | Code | Homepage | Demo video | BibTeX
Khoury Vis Lab — Northeastern University
* West Village H, Room 302, 440 Huntington Ave, Boston, MA 02115, USA
* 100 Fore Street, Portland, ME 04101, USA
* Carnegie Hall, 201, 5000 MacArthur Blvd, Oakland, CA 94613, USA